MapReduceでググたら、下記の説明文が出てきました:
MapReduce(マップリデュース)は、コンピューター機器のクラスター上での巨大なデータセットに対する分散コンピューティングを支援する目的で、Googleによって2004年に導入されたプログラミングモデルである。
分散コンピュータリング処理のことらしい。実際どんなふうに分散するでしょうか?
下の図がとてもわかりやすく説明できていると思います。
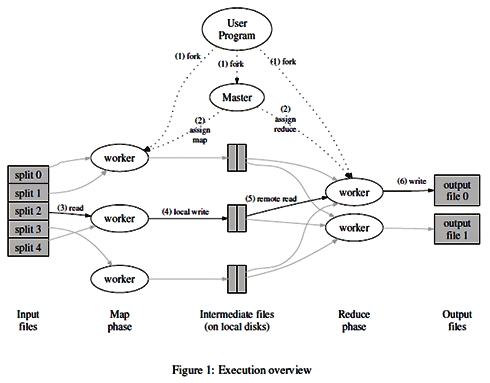
※From ITMedia
やりたいこととしては、Inputを処理して、Outputを出したい。
その手順は下記のイメージ:
①Inputを分割して、複数のworkerにアサインする(Readステップ)
②それぞれのworkerが決められたルールで自分をのnputをさらに分割する(Mapステップ)
③Mapステップで処理した結果をもらって、複数のworkerがOutputをだすために処理を行う(Reduceステップ)
④Reduceで処理した内容をOutputに変換する(Writeステップ)
この処理フローは順次実行のプログラムより複雑のように見えますが、
ビッグデータを処理する際は、この処理フローを使うと、複数のスレッドまたはサーバに分散&並列処理ができます。
※MapとReduceのロジックだけ考えればいい
http://www.atmarkit.co.jp/ait/articles/0807/08/news119.html
https://ja.wikipedia.org/wiki/MapReduce
